If AI Writes Your Code, the IP Has Already Moved
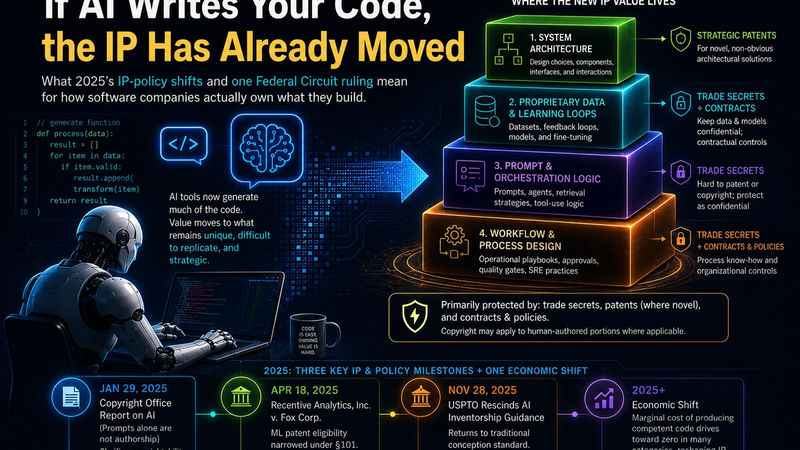
The legal ground under software IP shifted in two major ways in 2025, and most corporate playbooks have not caught up. The January 2025 Copyright Office Part 2 report clarified that prompting alone is not sufficient human authorship and that purely AI-generated outputs are not copyrightable, narrowing the practical scope of copyright protection for heavily AI-generated code. The April 2025 Recentive Analytics decision, with cert denied by the Supreme Court in December 2025, held that applying generic ML to a new data environment does not satisfy § 101 patent eligibility absent a technical improvement to the machine learning itself. And in November 2025 the USPTO rescinded its 2024 AI-inventorship guidance entirely, returning to the traditional conception standard, which in many single-inventor AI cases is operationally stricter, not looser. The underlying economic shift is larger than either legal update: with 42% of committed code now AI-generated, the code itself is increasingly a commodity layer, and defensible value is migrating to system architecture, proprietary data and learning loops, prompt and orchestration logic protected as trade secrets, and workflow design. This article maps both the legal updates and the economic shift, acknowledges what is still in flux, and provides a five-part playbook for executives whose IP discipline was built for a different production economics than the one they actually operate in.

Brandon Wilburn
May 13, 2026
The uncomfortable number nobody wants to dwell on
In Sonar's 2026 State of Code survey of more than 1,100 professional developers, 42% of code being committed today is AI-generated or AI-assisted, and that share is projected to reach 65% by 2027. Stack Overflow's 2025 Developer Survey found 84% of developers using or planning to use AI tools, up from 76% the prior year. Sonar's survey added a more telling number: only 48% of developers always verify AI-generated code before committing it, and 96% say they do not fully trust the output.
A term of art has crystallized for the extreme end of the spectrum. Vibe coding, where a human describes a desired program in prose and a model writes the implementation, is no longer a curiosity. It is the default workflow for a meaningful share of prototypes, internal tools, and shipped product features. The agentic coding tools from the major labs, Anthropic's Claude Code and OpenAI's Codex among them, now plan and execute multi-step coding tasks with minimal direct authorship by the human in the loop.
If you run an engineering organization, this should rearrange how you think about intellectual property. Not because AI secretly destroys your IP, but because it exposes an assumption that nobody bothered to test for forty years: that the code itself was ever the most valuable thing you owned.
Mostly it wasn't. You just never had to notice. Code was scarce, took skilled humans months to produce, and ran on machines that competitors couldn't easily replicate. Owning the source felt indistinguishable from owning the business. Now the production cost has collapsed, and U.S. authorities have made three significant moves on AI and IP in 2025: a Copyright Office report in January, a binding Federal Circuit ruling in April, and a USPTO inventorship guidance rescission in November. Most enterprise IP playbooks were written for a different production economics and a different doctrinal posture than the one in front of them now.
The strategic answer is not to give up on IP. It is to recognize that IP has relocated, away from the code artifact and toward the system around it. This essay maps the three policy and doctrinal moves that changed the operating assumptions in 2025, the economic shift that was already happening underneath them, and a practical playbook for protecting what is actually defensible now.
How we got here
For most of the modern software era, copyright was the default protection for code. The 1976 Copyright Act treats computer programs as literary works, and the Apple v. Franklin line of cases in the 1980s settled that both source and object code are eligible for copyright. Registration was cheap, automatic on creation, and offered statutory damages that made even small infringement claims worth bringing. Most enterprises never seriously thought about patents for ordinary software because copyright handled the easy cases and patent law was hostile to abstract software claims after Alice in 2014.
Then generative AI broke two things at once.
The first crack appeared in patent law. In 2022, the Federal Circuit decided Thaler v. Vidal, holding that under the Patent Act, an inventor must be a natural person and that an AI system cannot be listed as an inventor. The case involved a researcher who attempted to list his AI system "DABUS" as the inventor on two patent applications. The USPTO refused, the district court affirmed, and the Federal Circuit affirmed again. Thaler did not say AI-assisted inventions were unpatentable. It said only humans qualified as inventors, leaving open how much human contribution would actually be required.
The USPTO tried to answer that question in February 2024. Under then-Director Kathi Vidal, the office issued Inventorship Guidance for AI-Assisted Inventions that imported the Pannu v. Iolab factors, originally a joint-inventorship test, into single-inventor AI scenarios. The result was a "significant contribution" framework that asked whether a human had contributed meaningfully to conception of the claimed invention even when working alongside an AI system. For nearly two years, IP teams built playbooks around that framework.
The second crack opened on the copyright side. On January 29, 2025, the U.S. Copyright Office released Part 2 of its Report on Copyright and Artificial Intelligence, focused on copyrightability of AI-generated outputs. The headline conclusion was that purely AI-generated outputs are not copyrightable, that prompts alone do not provide sufficient human control to make a user the author of the resulting output, and that the legal question for any AI-assisted work is whether a human "determined sufficient expressive elements" of the final work. The Office declined to recommend any new statutory protection for AI-generated material.
Three months later, in April 2025, the Federal Circuit decided Recentive Analytics, Inc. v. Fox Corp., an issue of first impression in patent eligibility for machine learning. The panel held that claims that do no more than apply established methods of machine learning to a new data environment are not patent eligible under 35 U.S.C. § 101. The Supreme Court denied certiorari in December 2025 without commenting on the merits, leaving Recentive as binding Federal Circuit precedent.
Then, on November 28, 2025, the USPTO rescinded the February 2024 inventorship guidance in its entirety. The revised guidance, issued pursuant to Executive Order 14179, returned the office to the traditional Burroughs Wellcome conception standard and explicitly rejected applying the Pannu factors to single-inventor AI scenarios. AI systems are treated as instruments, "analogous to laboratory equipment, specialized software, or a research database," used by human inventors who must independently meet the traditional conception test.
The legal map at the start of 2026 is therefore quite different from the one most corporate IP playbooks reflect. The practical path to claiming copyright protection over heavily AI-generated code is narrower, more fact-dependent, and more dependent on documented human contribution than many enterprise teams assumed. The patent inventorship standard is doctrinally cleaner but operationally stricter in single-inventor AI cases. And one Federal Circuit decision has raised the § 101 bar for claims that merely apply generic machine learning techniques to a new data environment. None of this destroys IP in software. But it forces a much more deliberate accounting of what is actually being protected and how.
Copyright after January 2025: the default became harder to rely on
Copyright has been the workhorse protection for most enterprise software, and the January 2025 Copyright Office report introduced substantial uncertainty about how much of that protection actually attaches to the AI-generated portions of modern codebases.
The Office's central position, in current guidance and registration practice, is that prompting alone, even with detailed and iterative prompts, does not constitute sufficient human authorship for the output to qualify for copyright. The reasoning is that the user does not control how the machine translates the prompt into the specific expressive elements of the output. A human who instructs a generative system to "write a function that deduplicates entries in a list while preserving order" has not authored the resulting twenty lines of Python in any meaningful sense under current registration practice. The user controlled the goal. The model determined the specific expressive choices: variable names, control flow, edge-case handling, structural decomposition. Authorship, in the Office's view, attaches to whoever picks the expressive choices, not to whoever specifies the desired result.
The Office did acknowledge several categories that can still produce copyrightable work. A human modifying or arranging AI output in a way that reflects creative judgment can hold copyright in the resulting arrangement. A human whose own copyrightable work is perceptible in the AI output can claim copyright in that perceptible portion. And human-authored portions of a mixed work remain protected even when AI-generated portions of the same work are not.
For software, this is harder than it sounds. Code expression is more constrained than visual or literary art. The space of valid implementations of a given function is narrow, and the differences between two competent implementations of the same algorithm often come down to formatting and variable naming, neither of which carries much copyright weight even in fully human-authored code. A developer who reviews and lightly edits an AI-generated function has plausibly contributed less than a developer who reviews and lightly edits a colleague's pull request, and even the latter case has never been a strong copyright story for the editor.
Carlton Fields, in an April 2026 Bloomberg Law piece, captured the operational implication: the strategies that do best under the new regime involve "bespoke curation into a creative whole from many options." That is real work, and some software organizations do it. But most enterprise codebases are not curated in that sense. They are committed, reviewed, and shipped, often with the human review happening on autopilot. The Sonar data is telling here: 38% of developers report that reviewing AI-generated code takes more effort than reviewing human-written code, and only 48% always verify it before committing. The pattern that produces unambiguous human authorship is the opposite of the pattern most teams have actually adopted.
The practical result is a copyright registration story that will not hold up cleanly in litigation if it has to be tested. A registration that does not disclose AI-generated material when more than a de minimis portion exists is potentially invalid under the Office's own disclosure rules. A registration that does disclose it must accurately describe the human contribution, and "I prompted and reviewed" is not a contribution the Office has signaled it will credit.
This matters in concrete commercial situations. Statutory damages and attorneys' fees under copyright are only available for registered works. Without them, infringement litigation pencils out very differently. A clean copyright on a codebase has historically been the foundation under license enforcement, against both pirates and customers who exceed their license terms. That foundation is now partially cracked, and the cracks widen as the AI share of any given codebase grows.
The GitHub Copilot litigation is worth watching as the inverse case. In Doe v. GitHub, plaintiffs alleged that Copilot reproduced copyrighted code without preserving the required attribution and license notices, primarily as a DMCA § 1202(b) claim for removal of copyright management information. Judge Tigar dismissed the DMCA § 1202(b) claims, which were the principal copyright theory in the case, finding that the output was not similar enough to the plaintiffs' code to support liability under that section. He allowed the breach-of-contract and open-source license violation claims to proceed. The case is still evolving and is now on interlocutory appeal at the Ninth Circuit, where the central question is whether § 1202(b) requires identicality between input and output. Taken together with the January 2025 Copyright Office position, the strategic direction looks consistent even where the binding law is not yet settled: copyright is becoming a less predictable lever on both ends of the transaction, and license terms and contracts are absorbing more of the work copyright used to do.
Patents after November 2025: doctrinally clean, operationally strict
The patent picture is in some ways less dramatic and in other ways more important.
The November 2025 USPTO guidance does two things at once. First, it formally rescinds the 2024 framework that asked whether a single human had made a "significant contribution" via Pannu factors. Second, it reaffirms that the same conception standard applies to all inventions whether AI was used or not. As the Mayer Brown analysis put it, there is "no separate or modified legal standard for inventorship in AI-assisted contexts."
This sounds like a relaxation, and politically it was framed as one under Executive Order 14179's mandate to remove barriers to AI innovation. In practice, for a meaningful subset of cases, it is the opposite of a relaxation. The 2024 guidance, by importing Pannu, gave AI-assisted inventors a partial-credit framework. A human who made a significant contribution to one aspect of an invention could be named, even if AI did substantial work elsewhere. The 2025 guidance restores the traditional rule: a human inventor must have conceived the complete invention, with a "definite and permanent idea" sufficiently developed that only ordinary skill would be needed to reduce it to practice.
An IPWatchdog analysis of the rescission caught the implication clearly: a single human using AI tools to develop an invention now has to satisfy the full conception test on their own. Joint inventorship rules, including Pannu, only apply when multiple humans are involved. If your AI did most of the conceptual work and a single engineer prompted and curated, the traditional standard is harder to meet, not easier. The Federal Circuit's Burroughs Wellcome line requires conception to be specific and contemporaneous, and conception is what is tested when patent validity is challenged.
The second piece of the patent picture is Recentive Analytics. The four patents at issue in Recentive claimed methods for using machine learning to generate event schedules and television network maps. The Federal Circuit held that these claims merely applied generic ML techniques to a new data environment without disclosing any technological improvement to the ML itself, and therefore failed at Alice step one. Iterative training and dynamic model adjustment, the court held, are not alone a technological improvement under Alice/Mayo.
The Supreme Court declined to revisit this in December 2025, leaving Recentive as binding circuit law. The combined operational message from both Recentive and the November 2025 USPTO guidance is consistent. Patents on AI-assisted inventions remain available, but they require two things that ordinary AI applications rarely have: a human who can prove particularized conception of the claimed invention, and an underlying technical improvement that goes beyond plugging existing models into a new domain.
This is not bad news in absolute terms. It is, however, very different news than most enterprise IP teams are prepared for. The patents that get filed easily under this regime are not "method for using LLMs to optimize X" claims. They are claims directed at novel architectures, novel training procedures, novel orchestration mechanisms, or novel domain integrations that themselves represent a technical advance. Those exist, but they tend to live in small parts of any given codebase and require careful drafting.
The Wilmer Hale analysis of Recentive drew the right strategic conclusion: for many machine learning innovations, trade secrecy will be a better fit than patent. Patents require public disclosure of the invention. If the patent will fail at § 101 anyway, you have given away the disclosure and gained nothing. That tradeoff favors keeping more of the work private.
Why code was already weakening as IP, independent of any of this
If the legal story stopped here, the conclusion would be that some forms of software IP got narrower in 2025. The deeper point is that an economic shift had already been narrowing the same protections for several years, and the legal updates were partly catching up to it.
The argument is structural. Intellectual property protections derive their economic value from the scarcity they enforce. Copyright in code matters when reproducing or substantially copying the code is the cheapest path to a competing product. Patents on a technique matter when the technique is hard to invent and the patent forecloses cheap workarounds. As long as competent code is scarce, ownership of any particular implementation has real commercial weight.
AI coding tools have driven the marginal cost of producing competent code toward zero in a meaningful number of categories. For undifferentiated infrastructure, glue code, CRUD endpoints, conventional UI components, integration adapters, and the long tail of code that implements well-documented patterns, a capable model can now produce a working version in seconds. The major coding models have been trained on enough public implementations of similar code that their outputs tend to converge on idiomatic patterns. Two engineers using the same model, the same prompt, and the same product spec will produce substantially similar implementations.
This is the Stratechery move, applied to code: when the cost of producing a thing drops to near zero, the thing stops being where value accrues. Value migrates to whatever remains scarce and complementary. For software, what remains scarce is not the implementation of any given function. It is the system that determines which functions exist, how they fit together, what data flows through them, and what feedback loops keep them improving.
The GitHub Copilot litigation makes this concrete from a different angle. Even when plaintiffs could show that Copilot was trained on their code, they could not show that the generated output was similar enough to their work to support direct copyright infringement. Judge Tigar's reasoning was that Copilot rarely memorized code and only did so with long, similar excerpts. The forensic point is interesting, but the strategic point is more important: in a regime where AI generates code by drawing on patterns from countless examples, two clean-room implementations of the same functionality are now genuinely common rather than suspiciously rare. The copyright signal is muddier in both directions.
A useful test for whether a given piece of code is worth treating as serious IP is to ask: could a capable AI engineering team, given our product spec and a year, reproduce this from a clean room without seeing our source? For a growing share of enterprise codebases, the honest answer to that question is "yes, and probably faster than that." In those categories, code is increasingly functioning as a commodity layer. What is not a commodity is what you have built around it.
This does not mean code does not matter. It means code is no longer the right place to draw the protective perimeter. The perimeter has to move to where defensibility actually lives.
Where the new IP actually lives
Four areas now carry most of the defensible IP value in modern software businesses. None of them is the codebase itself.
System architecture. The strongest patent candidates in the new regime are not claims on what the system does at a feature level, but claims on how the system is structured to do it. Multi-agent coordination architectures, novel orchestration mechanisms, adaptive routing layers that select among models based on cost, latency, or task fit, hybrid systems that combine learned and symbolic components, and domain-specific integrations that constitute a genuine technical advance. These can satisfy both the conception requirement (a human designed the architecture, with particular contributions documentable) and the Recentive technological-improvement requirement (the architecture itself is the advance, not just the choice of where to point existing ML). Even when not patented, well-designed architecture is genuinely hard to copy because reproducing it requires understanding why the choices were made, which is often more time-consuming than rebuilding from scratch.
Proprietary data and learning loops. This is the most compounding moat available in software today, and it has very little to do with intellectual property law as traditionally conceived. The value comes from accumulating data that no competitor has, paired with systems that turn that data into model improvements, then feed those improvements back into more data collection. Each cycle widens the gap. Trade secret law covers the data and the pipelines. Contract law covers the customer agreements that grant data rights. But the deeper protection is operational: the data is collected as a byproduct of running the business, and competitors cannot collect equivalent data without first running an equivalent business. This is not a moat that erodes when AI gets cheaper. It deepens.
Prompt and orchestration logic, held as trade secrets. Most enterprises have not learned to treat their prompt engineering, tool selection strategies, context injection patterns, and orchestration logic as serious IP. This is changing. A well-tuned set of prompts for a specific domain, paired with a carefully designed orchestration layer that selects tools, manages state, and handles errors, can outperform a naive implementation by a wide margin even using the same underlying models. This category is poorly suited to patents (often abstract, often hard to satisfy Recentive) and poorly suited to copyright (the expression is too constrained). It is well suited to trade secret protection, which has no expiration, requires no disclosure, and can be enforced against employees and partners through standard agreements. The discipline is operational: access controls, classification policies, deliberate decisions about what goes into public marketing, and clear contractor agreements.
Workflow and process design. The least visible category and often the most durable. An organization that has built genuinely effective AI-assisted development workflows, with human-in-the-loop validation calibrated to the actual risk profile of each code area, continuous evaluation pipelines, deployment safeguards specific to AI-generated code, and feedback mechanisms that capture where humans corrected AI output, has IP that is essentially invisible from the outside. Competitors cannot replicate it by hiring away engineers, because the IP lives in the connective tissue between roles, tools, and decisions. It lives in shared assumptions, in checklists that everyone follows without thinking about them, and in the small accumulated wisdom of "we tried that and it didn't work" that never makes it into any document. This is the category where the discipline of a high-performing engineering organization compounds into something genuinely hard to copy.
The common pattern across all four categories is that the defensible asset is not a single artifact you can hand to a lawyer for protection. It is a system, an accumulation, a practice, or an architecture. The legal protections that apply, primarily trade secret and contract, are structurally less visible than copyright registrations or patent filings. This is uncomfortable for organizations whose IP discipline has been built around producing artifacts that lawyers can file. It is also where the value is actually moving.
The enterprise playbook
Five concrete moves follow from this analysis. None of them is exotic. The reason most enterprises are not yet doing them well is that they require coordinated changes across engineering, legal, and operations, and most IP programs are still calibrated to a world that no longer exists.
1. Document human conception in advance, not after the fact. If patents are part of your strategy, the November 2025 guidance puts a high premium on contemporaneous evidence that a named human inventor actually conceived the invention with particularity. Architecture decision records, design documents that predate implementation, written conception statements from inventors describing what they understood the invention to be at the point of conception, and AI usage logs that distinguish ideation from execution are all useful. The bar is the Burroughs Wellcome "definite and permanent idea of the complete and operative invention" standard, tested in litigation by the inventor's ability to describe the invention with particularity. That description has to be credible, and the easiest way to make it credible is to have written it down before the patent was filed.
2. Treat AI as a tool in all internal and external documentation. The USPTO and Copyright Office operate under different statutes, but their current positions point in the same practical direction: AI should be documented as an instrument used by a human, not as a legal author or inventor. Internal documentation that describes AI as having "designed," "invented," or "created" anything is creating discovery problems for litigation later. The right framing is consistent across copyright applications, patent filings, inventor declarations, and engineering documents: a human did the work, AI helped with execution. This is not legal pretense if it is actually true. The discipline is making it actually true by ensuring humans are present at the conception stage and documenting their contribution, then describing the work accurately in all subsequent materials.
3. Shift filings from code-level to system-level. A patent on a generic AI application of an existing technique is now likely to fail at § 101 under Recentive. A patent on a specific architectural improvement, a novel orchestration mechanism, or a hybrid system with a genuine technical advance is more defensible. The shift is from filing on "what the system does" to filing on "how the system is structured to do it." Copyright registrations should follow similar logic: register the human-authored portions of the codebase carefully, disclose AI-generated portions accurately, and stop treating registration as a perfunctory step.
4. Build trade-secret discipline deliberately. Most software organizations have weak trade secret practices because they relied on copyright as the default protection. With copyright partially eroded for AI-generated code and patent eligibility tighter under Recentive, trade secrets are doing more of the work. The legal requirements are real: reasonable measures to keep the information secret, identifiable boundaries on what is and is not protected, and consistent treatment in employee and contractor agreements. The operational requirements are higher: access controls scaled to the value of the information, classification of internal documents, deliberate decisions about what to publish, and offboarding processes that actually enforce the agreements. Trade secrets do not expire and do not require disclosure, which makes them the right protection for the orchestration logic, prompt frameworks, data pipelines, and evaluation systems where most modern IP value lives.
5. Audit training-data and license exposure. AI coding tools have created a new category of license compliance risk. A GPL-licensed snippet reproduced into your proprietary codebase by an AI assistant does not stop being a compliance issue because a machine wrote it. The GitHub Copilot court allowed breach-of-license claims to proceed even after dismissing the copyright theories, signaling that open-source licenses can be enforced as contracts when AI tools produce output that violates the license terms. The right enterprise response is a coordinated effort across legal, engineering, and procurement: understand what each AI coding vendor has said about training data, indemnification, and "filter" features for public-code matches; audit which tools are in use and on which codebases; and treat AI-generated code as needing the same license review that human-written code that draws on external sources would receive.
These five moves are not difficult individually. The reason they are uncommon as a coherent program is that they require executives to decide that IP is no longer primarily a legal function. It is a cross-functional discipline that touches engineering practice, organizational design, vendor selection, and data strategy. Treating it as such is the upstream change that makes any of the downstream tactics actually work.
What is still in flux
The directional argument in this essay is, I think, on solid ground. The specific legal doctrines underneath it are not all settled, and any executive playbook should be built with the expectation that several pieces will shift again in the next eighteen months.
Several open fronts are worth tracking. The AI training-data cases are the largest. Doe v. GitHub is on interlocutory appeal at the Ninth Circuit and turns partly on whether DMCA § 1202(b) requires "identicality" between training input and model output, a question on which district courts have split. A series of higher-profile cases against the major model providers, including the New York Times litigation against OpenAI and the various authors' suits, will produce appellate rulings on fair use, market substitution, and the scope of license terms over the next two to three years. Any of those could substantially change how enterprises that build on top of foundation models should think about license risk, indemnification, and acceptable use.
Patent doctrine is similarly in motion. Recentive is binding in the Federal Circuit but represents an issue of first impression, and subsequent panels could narrow or refine it. The USPTO's November 2025 guidance is itself the second swing in two years, and a future administration could swing it back. Congress has shown intermittent interest in legislating directly on AI patent eligibility, and the §101 reform conversation has been live in some form since the original Alice decision. None of these are imminent, but they are not stable either.
The international picture adds another layer. The EU AI Act, the UK's evolving position on AI inventorship, and the differing approaches in Japan, China, and Singapore mean that any company filing globally is navigating multiple regimes that do not align. The U.S. treatment of AI as a tool sits within a broader international landscape where jurisdictions differ on authorship, inventorship, training-data liability, and ownership of AI-assisted outputs, and a multinational IP strategy has to plan for that divergence.
Licensing frameworks for AI-generated and AI-trained content are also being built in real time. The emergence of model-output licensing terms from foundation-model vendors, the AI-training-data licensing deals that have started to appear in the publishing industry, and the new generation of open-source licenses that specifically address AI training are all changing the contract environment in which the IP discussion sits. The pieces of the playbook in this essay that lean on contract and trade secret will continue to work. The pieces that lean on copyright and patent should be revisited annually.
The honest summary is that the strategic direction has more durability than any single legal holding underneath it. The marginal cost of producing competent code in broad categories is unlikely to return to pre-generative-AI levels. The location of defensible value in software is not going to move back to the code artifact. Those facts will hold even as the case law churns. The legal updates of 2025 are best read as the first round of doctrinal catch-up to an economic shift that is still in progress.
The two failure modes, and one closing test
Two mistakes dominate enterprise responses to this shift.
The first is treating AI as fatal to IP. The reasoning is roughly: if we cannot reliably copyright the code and patents are hard to get, why bother investing in IP discipline at all? This produces sloppy documentation, weak trade secret practices, registrations that will not hold up if tested, and eventually discovery problems in litigation that could have been avoided with modest discipline earlier. The argument has surface appeal but misreads the situation. IP has not disappeared. It has moved, and the new locations are protectable, just differently.
The second mistake is treating AI-generated code as if nothing has changed. This produces copyright registrations that do not disclose AI material, patent filings whose inventorship will not survive scrutiny, internal playbooks built on USPTO guidance that has already been withdrawn, and engineering practices that quietly assume copyright protection on code that no longer reliably has it. This is the more common mistake in 2026 because it is the path of least operational resistance.
The accurate position sits between them. The organizations that get this right will be quieter about their IP than they used to be, because much of the new value sits in things you do not publicize. They will file fewer patents but file them on stronger subjects. They will register copyrights more carefully and rely on them less. They will invest more in trade secret discipline and operational moats than in the artifacts that get filed.
The old test for IP quality was "could we enforce this in court?" That still matters, but it is no longer sufficient. The new test is closer to: if a competitor had our product spec and a capable AI engineering team, what would still take them two years to replicate? Whatever is on that list is your real intellectual property. Everything else is increasingly a commodity, and pretending otherwise is its own kind of strategic risk.
You no longer win by owning the code. You win by owning the system that keeps producing better code than anyone else can, faster than anyone else can, with data and judgment and operational discipline that nobody else has.
And, critically, by being able to prove on paper, in advance and not after the fact, that a human mind designed it.
Tags
Affiliate Disclosure

About Brandon Wilburn
As a technology and business thought leader, Brandon Wilburn is currently the Chief Architect at Spirent Communications leading the Lifecycle Service Assurance business unit. He provides vision and drives the company's strategic initiates through customer and vendor engagements, value stream product deliveries, multi-national reorganization, cross-vertical engineering efficiencies, business development, and Innovation Lab creation.
Brandon works with CEOs, CTOs, GMs, R&D VPs, and other leaders to achieve successful business outcomes for multinational organizations in highly technical and challenging domains. He provides direct counsel to executives on markets, strategy, acquisitions, and execution.
With an effortless communication style that transcends engineering, technology, and marketing, Brandon is adept at engaging marquee customers, quickly building relationships, creating strategic alignment, and delivering customer value.
He has generated new multi-national R&D Innovation Lab organization from inception to scaled delivery, ultimately 70 resources strong with a 5mil annual budget, leveraging FTEs and consulting talent from United States, Canada, United Kingdom, Poland, Lithuania, Romania, Ukraine, Russia, and India all delivering new products together successfully. He directed and fostered the latest in best practices in organization structure, methodology, and engineering for products and platforms.
Brandon believes strongly in an organization's culture, organizing internal and external events such as Hackathons and Demo Days to support and propagate a positive the engineering community.